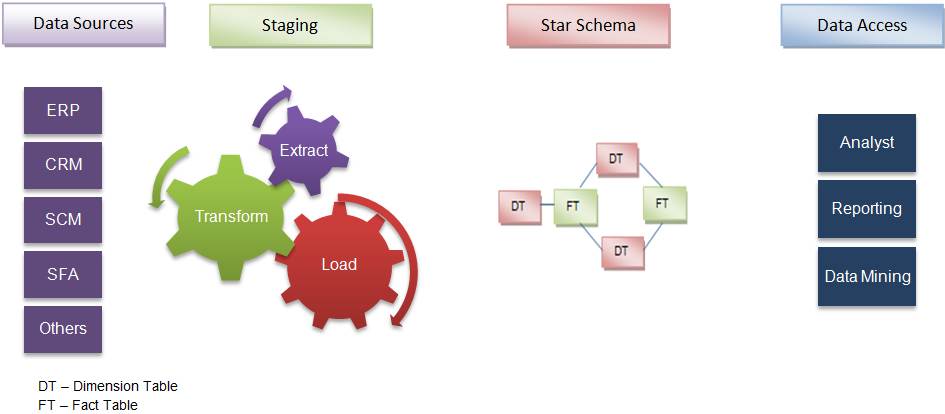
Data warehouse systems have
gained popularity as companies from the most varied industries realize how
useful these systems can be. A large number of these organizations, however,
lack the experience and skills required to meet the challenges involved in data warehousing
projects. In particular, a lack of a methodological approach prevents data warehousing
projects from being carried out successfully. Generally, methodological
approaches are created by closely studying similar experiences and minimizing
the risks for failure by basing new approaches on a constructive analysis of
the mistakes made previously.
Data warehouse design is one of the key technique in building the data
warehouse. Choosing a right data warehouse design can save the project time and
cost. Basically there are two data warehouse design approaches are popular.
1.5.1 Bottom-Up Design:
In the bottom-up design approach, the data marts are created first to provide reporting capability. A data mart addresses a single business area such as sales, Finance etc. These data marts are then integrated to build a complete data warehouse. The integration of data marts is implemented using data warehouse bus architecture. In the bus architecture, a dimension is shared between facts in two or more data marts. These dimensions are called conformed dimensions. These conformed dimensions are integrated from data marts and then data warehouse is built.
1.5.1.1 Advantages of bottom-up design are:
1.5.1 Bottom-Up Design:
In the bottom-up design approach, the data marts are created first to provide reporting capability. A data mart addresses a single business area such as sales, Finance etc. These data marts are then integrated to build a complete data warehouse. The integration of data marts is implemented using data warehouse bus architecture. In the bus architecture, a dimension is shared between facts in two or more data marts. These dimensions are called conformed dimensions. These conformed dimensions are integrated from data marts and then data warehouse is built.
1.5.1.1 Advantages of bottom-up design are:
1.
This model contains consistent data marts
and these data marts can be delivered quickly.
2.
As the data marts are created first,
reports can be generated quickly.
3.
The data warehouse can be extended easily
to accommodate new business units. It is just creating new data marts and then
integrating with other data marts.
1.5.1.2 Disadvantages of bottom-up design are:
The positions of the data warehouse and the data marts are reversed in
the bottom-up approach design.
1.5.2 Top-Down Design:
In the top-down design approach the, data warehouse is built first. The data marts are then created from the data warehouse.
1.5.2.1 Advantages of top-down design are:
In the top-down design approach the, data warehouse is built first. The data marts are then created from the data warehouse.
1.5.2.1 Advantages of top-down design are:
1.
Provides consistent dimensional views of
data across data marts, as all data marts are loaded from the data warehouse.
2.
This approach is robust against business
changes. Creating a new data mart from the data warehouse is very easy.
1.5.2.2 Disadvantages of top-down design
are:
1. This
methodology is inflexible to changing departmental needs during implementation
phase.
2. It
represents a very large project and the cost of implementing the project is
significant.
1.5.3 Top-Down vs. Bottom-Up
When you consider methodological
approaches, their top-down structures or bottom-up structures play a basic role
in creating a data warehouse. Both structures deeply affect the Data
Ware house lifecycle.
If you use a top-down approach, you will
have to analyze global business needs, plan how to develop
a data warehouse, design it, and implement it as a whole.
This procedure is promising: it will achieve excellent results because it is
based on a global picture of the goal to achieve, and in principle it ensures
consistent, well integrated data warehouses. However, a long story of
failure with top-down approaches teaches that:
- High-cost estimates with
long-term implementations discourage company managers from embarking on
these kind of projects;
- Analyzing and bringing
together all relevant sources is a very difficult task,
also because it is not very likely that they are all available and stable
at the same time;
- It is
extremely difficult to forecast the specific needs of every department
involved in a project, which can result in the analysis process coming to
a standstill;
- Since no prototype is going to
be delivered in the short term, users cannot check for this project to be
useful, so they lose trust and interest in it.
In a bottom-up approach, data warehouses are
incrementally built and several data marts are iteratively created.
Each data mart is based on a set of facts that are linked to a
specific company department and that can be interesting for a user subgroup
(for example, data marts for inventories, marketing, and so on). If
this approach is coupled with quick prototyping, the time and cost needed for
implementation can be reduced so remarkably that company managers will notice
how useful the project being carried out is. In this way, that project will
still be of great interest.
The bottom-up approach turns out to be
more cautious than the top-down one and it is almost universally accepted.
Naturally the bottom-up approach is not risk-free, because it gets a partial
picture of the whole field of application. We need to pay attention to the
first data mart to be used as prototype to get the best results: this
should play a very strategic role in a company. In fact, its role is so crucial
that this data mart should be a reference point for the
whole data warehouse. In this way, the following data marts
can be easily added to the original one. Moreover, it is highly advisable that
the selected data mart exploit consistent data already made
available.