
Friday, September 13, 2019
Monday, January 21, 2019
Saturday, January 12, 2019
Dimensional Modeling Basics
2.1 Dimensional Modeling Basics
Dimensional modeling gets its name from
the business dimensions we need to incorporate into the logical data model. It
is a logical design technique to structure the business dimensions and the
metrics that are analyzed along these dimensions. This modeling technique is
intuitive for that purpose. The model has also proved to provide high
performance for queries and analysis. The multidimensional information package
diagram we have discussed is the foundation for the dimensional model.
Therefore, the dimensional model consists of the specific data structures
needed to represent the business dimensions. These data structures also contain
the metrics or facts.
To build a
dimensional database, you start with a dimensional data model. The dimensional
data model provides a method for making databases simple and understandable.
You can conceive of a dimensional database as a database cube of
three or four dimensions where users can access a slice of the database along
any of its dimensions. To create a dimensional database, you need a model that
lets you visualize the data.
Suppose your
business sells products in different markets and evaluates the performance over
time. It is easy to conceive of this business process as a cube of data, which
contains dimensions for time, products, and markets. Shows this dimensional
model. The various intersections along the lines of the cube would contain the measures of
the business. The measures correspond to a particular combination of product,
market, and time data.
FIGURE – 2.1: (A Dimensional Model of a Business
That Has Time, Product and Market Dimensions)
Another
name for the dimensional model is the star-join
schema. The database designers use this name because the diagram for this
model looks like a star with one central table around which a set of other
tables are displayed. The central table is the only table in the schema with
multiple joins connecting it to all the other tables. This central table is
called the fact table and the other tables are called dimension
tables. The dimension tables all have only a single join that attaches them
to the fact table, regardless of the query. shows a
simple dimensional model of a business that sells products in different markets
and evaluates business performance over time.
FIGURE – 2.2: (A Typical Dimensional Model)
2.2 Data
Warehousing - Fact and Dimension Tables
Data
warehouses are built using dimensional data models which consist of fact and
dimension tables. Dimension tables are used to describe dimensions; they
contain dimension keys, values and attributes. For example, the time dimension
would contain every hour, day, week, month, quarter and year that has occurred
since you started your business operations. Product dimension could contain a
name and description of products you sell, their unit price, color, weight and
other attributes as applicable.
Dimension tables are typically small,
ranging from a few to several thousand rows. Occasionally dimensions can grow
fairly large, however. For example, a large credit card company could have a
customer dimension with millions of rows. Dimension table structure is
typically very lean, for example customer dimension could look like following:
Table – 1 (Customer Dimension)
|
Customer_key
|
|
Customer_city
|
|
Customer_state
|
|
Customer_country
|
Although there might be other attributes that
you store in the relational database, data warehouses might not need all of
those attributes. For example, customer telephone numbers, email addresses and
other contact information would not be necessary for the warehouse. Keep in mind
that data warehouses are used to make strategic decisions by analyzing trends.
It is not meant to be a tool for daily business operations. On the other hand,
you might have some Reports that do include data elements that isn’t necessary
for data analysis.
Most
data warehouses will have one or multiple time dimensions. Since the warehouse
will be used for finding and examining trends, data analysts will need to know
when each fact has occurred. The most common time dimension is calendar time.
However, your business might also need a fiscal time dimension in case your
fiscal year does not start on January 1st as the calendar year.
Most
data warehouses will also contain product or service dimensions since each
business typically operates by offering either products or services to others.
Geographically dispersed businesses are likely to have a location dimension.
Fact
tables contain keys to dimension tables as well as measurable facts that data
analysts would want to examine. For example, a store selling automotive parts
might have a fact table recording a sale of each item. The fact table of An
educational entity could track credit hours awarded to students. A bakery could
have a fact table that records manufacturing of various baked goods.
Fact
tables can grow very large, with millions or even billions of rows. It is
important to identify the lowest level of facts that makes sense to analyze for
your business this is often referred to as fact table "grain". For
instance, for a Healthcare billing company it might be sufficient to track
revenues by month; daily and hourly data might not exist or might not be relevant. On the other hand,
the assembly line warehouse analysts might be very concerned in number of
defective goods that were manufactured each hour. Similarly a marketing data
warehouse might be concerned by the activity of a consumer group with a
specific income-level rather than purchases made by each individual.
2.2.1 Fact Table
Facts: A fact
is a measurement captured from an event (transaction) in the marketplace. It is
the raw materials for knowledge – observations.
A customer buys a product at a certain location at a certain time. When the
intersection of these four dimensions occurs, a sale is made. The sale is
describable as amount of dollars received, number of items sold, weight of
goods shipped, etc. – a quantity that can be added to other sales similar in
definition. Thus, a meaningful and measurable event of significance to the business
occurs at the intersection point of business dimensions. It is the fact. We use
the fact to represent a business measure. A data warehouse fact is defined as an
intersection of the dimensions constituting the basic entities of the business
transaction. It is not easy to show the intersection of more than three
dimensions in a diagram, but facts in a data warehouse may originate from many
dimensions.
Fact Table: A fact
table is used in dimensional model in data warehouse design.
A fact table is found at the center of a star schema or snowflake schema surrounded by dimension tables. A fact
table consists of facts of a particular business process e.g., sales revenue by
month by product. Facts are also known as measurements or metrics. A fact table
record captures a measurement or a metric.
Example of fact table:
In the schema below, we have fact table
FACT_SALES that has a grain
which gives us a number of units W sold by date, by store and by product. All
other tables such as DIM_DATE, DIM_STORE and DIM_PRODUCT are
dimensions tables. This schema is known as star schema.
Here is overview
of four steps to design a fact table described by Kimball:
- Choosing business process to model – The first step
is to decide what business process to model by gathering and understanding
business needs and available data
- Declare the grain – by declaring a grain means describing exactly
what a fact table record represents
- Choose the dimensions – once grain of fact table is stated clearly, it
is time to determine dimensions for the fact table.
- Identify facts – identify carefully which facts will appear in
the fact table.
FIGURE – 2.3: (Fact Table with Star Scheme)
2.2.2 Dimensional Table
A dimension is a
structure, often composed of one or more hierarchies, that categorizes data.
Dimensional attributes help to describe the dimensional value. They are
normally descriptive, textual values. Dimension tables are generally small in
size as compared to fact table.
Hierarchies and categories are included in
the information packages for each dimension.
Let us examine the product dimension. Here, the product is the basic
automobile. Therefore, we include the data elements relevant to product as
hierarchies and categories. These would be model name, model year, package
styling, product line, product category, exterior color, interior color, and first
model year. Looking at the other business dimensions for the auto sales
analysis, we summarize the hierarchies and categories for each dimension as
follows:
1.
Product: Model name, model
year, package styling, product line, product category, exterior Color, interior
color, first model year.
2.
Dealer: Dealer name, city,
state, single brand flag, date first operation.
3.
Customer demographics: Age, gender, income range,
marital status, household size,
Vehicles owned, home value, own or
rent.
4.
Payment method: Finance type, term in months,
interest rate, agent.
5.
Time: Date, month, quarter, year, day of week, day of month, season,
holiday flag Let us go back to the hotel occupancy analysis. We have included
three business dimensions. Let us list the possible hierarchies and categories
for the three dimensions.
6.
Hotel: Hotel line, branch
name, branch code, region, address, city, state, Zip Code, Manager,
construction year, renovation year
7.
Room type: Room type, room
size, number of beds, type of bed, maximum occupants, Suite, refrigerator,
kitchenette
8.
Time: Date, day of month,
day of week, month, quarter, year, holiday flag.
Wednesday, January 9, 2019
Types of Meta Data
Types of Meta Data (According to Arun K.
Pujari):
1.7.1.1
Build Time Meta Data
At the time of
data DWH designing and building, the metadata that we generate can be termed as
build time meta data. This metadata links business and Ware house terminology
and describe the data technical structure. IT is most detailed and exact type
of meta data and is used extensively by ware house designer, developer and
administrator.
1.7.1.2
Usage Meta Data
When the ware
house is in production, usage meta data, which is derived from built time meta
data is an important tool for users and data administrator.
1.7.1.1
Control Meta Data
This metadata is
used by databases and other tools to manage their own operation. Control
metadata are used by system programmer only. It provides vital information
about the timelines of ware house data and helps user track the sequence and
timing of ware events.
Ex:
Suppose
a copy of build time meta data catalog I maintained DBMS for the internal
representation. This will be called control metadata.
Meta Data
The first image most people have of the
data warehouse is a large collection of historical,
integrated data. While that image is correct in many regards, there is another very important element of the data warehouse
that is vital - metadata.
Metadata is data about data. Metadata has been
around as long as there have been programs
and data that the programs operate on. Figure 1 shows metadata in a simple
form.

While metadata is not new, the role of
metadata and its importance in the face of the data warehouse certainly is new.
For years the information technology professional has worked in the same
environment as metadata, but in many ways has paid little attention to
metadata. The information professional has spent a life dedicated to process
and functional analysis, user requirements, maintenance, architectures, and the
like. The role of metadata has been passive at best in this milieu.
But metadata plays a very different role in
data warehouse. Relegating metadata to a backwater, passive role in the data
warehouse environment is to defeat the purpose of data warehouse. Metadata
plays a very active and important part in the data warehouse environment.
The reason why metadata plays such an
important and active role in the data warehouse environment is apparent when
contrasting the operational environment to the data warehouse environment
insofar as the user community is concerned.
It serve to identify the contents and
location of data in the ware house metadata us bridge between the DWH and
decision support system application. Meta data is needed to provide an
unambiguous interpretation. Metadata provide a catalogue of data in the DHW and
pointer to this data. Meta data is used
to building, maintaining, managing, and using DWH.
Meta Data
repository should contain:
1. A
description of the structure of the DWH. This includes ware house schemes, view, dimensions,
hierarchies and derived data definition, data marts etc.
2. Operational
meta data such as data linkage, currency of data and monitoring information.
3. Summarization
processes which include dimension definition. Data on granularity partitions,
summary measure etc.
4. Detail
of data source which includes source databases and their content, gateway
description, a data partitions, data extractions etc.
5. Data
related to system performance.
6. Business
meta data, which includes business terms and definition, data owner ship
information and changing policies.
Data Mart
A data mart is a
simple form of a data warehouse that is focused on a single subject (or
functional area), such as Sales, Finance, or Marketing. Data marts are often
built and controlled by a single department within an organization. Given their
single-subject focus, data marts usually draw data from only a few sources. The
sources could be internal operational systems, a central data warehouse, or
external data.
1.6.1 Dependent and Independent Data Mart
There are two basic types of data marts:
dependent and independent. The categorization is based primarily on the data
source that feeds the data mart. Dependent data marts draw data from a central
data warehouse that has already been created. Independent data marts, in
contrast, are standalone systems built by drawing data directly from
operational or external sources of data, or both.
The main difference between independent
and dependent data marts is how you populate the data mart; that is, how you
get data out of the sources and into the data mart. This step, called the
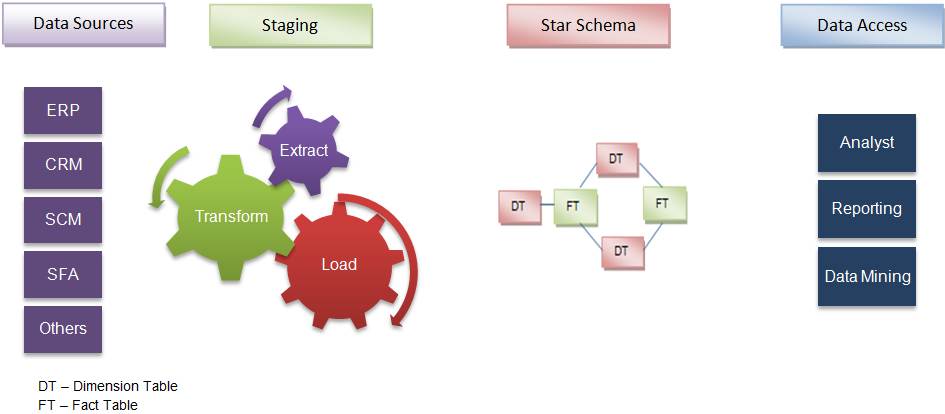
Extraction-Transformation-and Loading (ETL) process, involves moving data from
operational systems, filtering it, and loading it into the data mart.
With dependent data marts, this process is
somewhat simplified because formatted and summarized (clean) data has already
been loaded into the central data warehouse. The ETL process for dependent data
marts is mostly a process of identifying the right subset of data relevant to
the chosen data mart subject and moving a copy of it, perhaps in a summarized
form.
With
independent data marts, however, you must deal with all aspects of the ETL
process, much as you do with a central data warehouse. The number of sources is
likely to be fewer and the amount of data associated with the data mart is less
than the warehouse, given your focus on a single subject.
The motivations behind the creation of
these two types of data marts are also typically different. Dependent data
marts are usually built to achieve improved performance and availability,
better control, and lower telecommunication costs resulting from local access
of data relevant to a specific department. The creation of independent data
marts is often driven by the need to have a solution within a shorter time.
1.6.2 Difference between
Data Ware House and Data Mart
Table A Differences
Between a Data Warehouse and a Data Mart
|
Category
|
Data Warehouse
|
Data Mart
|
|
Scope
|
Corporate
|
Line of Business (LOB)
|
|
Subject
|
Multiple
|
Single subject
|
|
Data Sources
|
Many
|
Few
|
|
Size (typical)
|
100 GB-TB+
|
< 100 GB
|
|
Implementation Time
|
Months to years
|
Months
|
Top-Down vs. Bottom-Up In Data Warehousing
Data warehouse systems have
gained popularity as companies from the most varied industries realize how
useful these systems can be. A large number of these organizations, however,
lack the experience and skills required to meet the challenges involved in data warehousing
projects. In particular, a lack of a methodological approach prevents data warehousing
projects from being carried out successfully. Generally, methodological
approaches are created by closely studying similar experiences and minimizing
the risks for failure by basing new approaches on a constructive analysis of
the mistakes made previously.
Data warehouse design is one of the key technique in building the data
warehouse. Choosing a right data warehouse design can save the project time and
cost. Basically there are two data warehouse design approaches are popular.
1.5.1 Bottom-Up Design:
In the bottom-up design approach, the data marts are created first to provide reporting capability. A data mart addresses a single business area such as sales, Finance etc. These data marts are then integrated to build a complete data warehouse. The integration of data marts is implemented using data warehouse bus architecture. In the bus architecture, a dimension is shared between facts in two or more data marts. These dimensions are called conformed dimensions. These conformed dimensions are integrated from data marts and then data warehouse is built.
1.5.1.1 Advantages of bottom-up design are:
1.5.1 Bottom-Up Design:
In the bottom-up design approach, the data marts are created first to provide reporting capability. A data mart addresses a single business area such as sales, Finance etc. These data marts are then integrated to build a complete data warehouse. The integration of data marts is implemented using data warehouse bus architecture. In the bus architecture, a dimension is shared between facts in two or more data marts. These dimensions are called conformed dimensions. These conformed dimensions are integrated from data marts and then data warehouse is built.
1.5.1.1 Advantages of bottom-up design are:
1.
This model contains consistent data marts
and these data marts can be delivered quickly.
2.
As the data marts are created first,
reports can be generated quickly.
3.
The data warehouse can be extended easily
to accommodate new business units. It is just creating new data marts and then
integrating with other data marts.
1.5.1.2 Disadvantages of bottom-up design are:
The positions of the data warehouse and the data marts are reversed in
the bottom-up approach design.
1.5.2 Top-Down Design:
In the top-down design approach the, data warehouse is built first. The data marts are then created from the data warehouse.
1.5.2.1 Advantages of top-down design are:
In the top-down design approach the, data warehouse is built first. The data marts are then created from the data warehouse.
1.5.2.1 Advantages of top-down design are:
1.
Provides consistent dimensional views of
data across data marts, as all data marts are loaded from the data warehouse.
2.
This approach is robust against business
changes. Creating a new data mart from the data warehouse is very easy.
1.5.2.2 Disadvantages of top-down design
are:
1. This
methodology is inflexible to changing departmental needs during implementation
phase.
2. It
represents a very large project and the cost of implementing the project is
significant.
1.5.3 Top-Down vs. Bottom-Up
When you consider methodological
approaches, their top-down structures or bottom-up structures play a basic role
in creating a data warehouse. Both structures deeply affect the Data
Ware house lifecycle.
If you use a top-down approach, you will
have to analyze global business needs, plan how to develop
a data warehouse, design it, and implement it as a whole.
This procedure is promising: it will achieve excellent results because it is
based on a global picture of the goal to achieve, and in principle it ensures
consistent, well integrated data warehouses. However, a long story of
failure with top-down approaches teaches that:
- High-cost estimates with
long-term implementations discourage company managers from embarking on
these kind of projects;
- Analyzing and bringing
together all relevant sources is a very difficult task,
also because it is not very likely that they are all available and stable
at the same time;
- It is
extremely difficult to forecast the specific needs of every department
involved in a project, which can result in the analysis process coming to
a standstill;
- Since no prototype is going to
be delivered in the short term, users cannot check for this project to be
useful, so they lose trust and interest in it.
In a bottom-up approach, data warehouses are
incrementally built and several data marts are iteratively created.
Each data mart is based on a set of facts that are linked to a
specific company department and that can be interesting for a user subgroup
(for example, data marts for inventories, marketing, and so on). If
this approach is coupled with quick prototyping, the time and cost needed for
implementation can be reduced so remarkably that company managers will notice
how useful the project being carried out is. In this way, that project will
still be of great interest.
The bottom-up approach turns out to be
more cautious than the top-down one and it is almost universally accepted.
Naturally the bottom-up approach is not risk-free, because it gets a partial
picture of the whole field of application. We need to pay attention to the
first data mart to be used as prototype to get the best results: this
should play a very strategic role in a company. In fact, its role is so crucial
that this data mart should be a reference point for the
whole data warehouse. In this way, the following data marts
can be easily added to the original one. Moreover, it is highly advisable that
the selected data mart exploit consistent data already made
available.
Data Granularity
The
level of detail considered in a model or decision
making process. The greater the granularity, the
deeper the level of detail. Granularity is usually used to characterize the scale or level of detail in a set of data.
Les Barbusinski’s Answer: Granularity is usually mentioned in the context of dimensional data structures (i.e., facts and dimensions) and refers to the level of detail in a given fact table. The more detail there is in the fact table, the higher its granularity and vice versa. Another way to look at it is that the higher the granularity of a fact table, the more rows it will have.
Les Barbusinski’s Answer: Granularity is usually mentioned in the context of dimensional data structures (i.e., facts and dimensions) and refers to the level of detail in a given fact table. The more detail there is in the fact table, the higher its granularity and vice versa. Another way to look at it is that the higher the granularity of a fact table, the more rows it will have.
Let me illustrate with the following example: Say we have a
data mart with a single fact (Sales) and three dimensions (Time, Organization
and Product). The fact table contains three metrics (Unit Price, Units Sold and
Total Sale Amount). The Time dimension consists of four hierarchical elements
(Year, Quarter, Month and Day). The Organization dimension consists of three
hierarchical elements (Region, District and Store). The Product dimension consists
of two hierarchical elements (Product Family and SKU).
As always, the metrics in the Sales fact table must be
stored at some intersection of the dimensions (i.e., Time, Organization and
Product). Hence, in this data mart, the highest granularity that we can store
Sales metrics is by Day/Store/SKU (i.e., the lowest level in each dimensional
hierarchy). Conversely, the lowest granularity that we can aggregate Sales
metrics to in this data mart is by Year/Region/Product Family (i.e., the
highest level in each dimensional hierarchy). We may also (for a variety of
performance reasons) choose to store Sales metrics at some intermediate level
of granularity (e.g., by Month/District/SKU).
Chuck Kelley’s Answer: Granularity is the level of depth of
data. For example, you might have a date/time dimension which could be at the
year, month, quarter, period, week, day, hour, minute, second, hundredths of
seconds level of granularity. Most data warehouses do not go to the second or hundredths
of seconds level, but it could be possible. The granularity with be the lowest
level of the depth of data.
Joe Oates’ Answer: Granularity refers to the
level of detail of the data stored fact tables in a data warehouse. High
granularity refers to data that is at or near the transaction level. Data that
is at the transaction level is usually referred to as atomic level data. Low
granularity refers to data that is summarized or aggregated, usually from the
atomic level data. Summarized data can be lightly summarized as in daily or weekly
summaries or highly summarized data such as yearly averages and totals.
Clay Rehm’s Answer: Granularity simply means the
level of detail. A typical data warehouse will have some tables in it that have
a lot of detail and have other tables that are summarized or aggregated, which
means less detail. Each non- key column in a fact table must be at the same
level of granularity (detail). For example, if your primary measure on a
specific fact table is daily total sales, then that is defining the granularity.
Only when the grain for the fact table is chosen can we identify the dimensions
of that fact table.
Difference between Data ware House and DBMS
A
data warehouse is a database used to store data. It is a central repository of
data in which data from various sources is stored. A data warehouse is also
known as an enterprise data warehouse.
The
data warehouse is then used for reporting and data analysis. It can be used for
creating trending reports for senior management reporting such as annual and
quarterly comparisons.
The
purpose of a data warehouse is to provide flexible access to the data to the
user. Data warehousing generally refers to the combination of many different databases
across an entire enterprise. Data warehouses store current as well as
historical data, so that all of the relevant data may be used for analysis. The
analysis helps to find and show relationships among the data, to extract
meaning from the data.
A
database, on the other hand, is the basis or any data storage. It is an
organized collection of data. Data from various sources are collected in to a
single place, this place is the database. The data is organized into a
structure of some sort, mainly according to a database model. The most commonly
used database model is the relational model, others include hierarchical model,
network model, etc.
In
order to retrieve data from a database, one has to use a database management
system (DBMS). The database management systems are designed applications that
interact with the user, other applications, and the database itself to capture
and analyze data. The DBMS is designed to allow the definition, creation,
querying, update, and administration of databases. Some popular DBMSs include
MySQL, PostgreSQL, SQLite, Microsoft SQL Server, Microsoft Access, Oracle, etc.
While,
a database and a data warehouse may seem the same, they are actually different
is a key aspect. A database is used to store data while a data
warehouse is mostly used to facilitate reporting and analysis. Basically,
database is just where the data is stored; in order to access this data or
analyze it a database management system is required. However, a data warehouse
does not necessarily require a DBMS. The purpose of a data warehouse is for
easy access to the data for a user. The data warehouse may also be used to
analyze the data; however the actual process of analysis is called data mining.
2.
A
data warehouse is used for Online Analytical Processing (OLAP). This reads the
historical data for the Users for business decisions.
3.
In
a database the tables and joins are complex since they are normalized for RDMS.
This reduces redundant data and saves storage space.
4.
In
data warehouse, the tables and joins are simple since they are de-normalized.
This is done to reduce the response time for analytical queries.
5.
Relational
modeling techniques are used for RDMS database design, whereas modeling
techniques are used for the Data Warehouse design.
6.
A
database is optimized for write operation, while a data warehouse is optimized
for read operations.
7.
In
a database, the performance is low for analysis queries, while in a data
warehouse, there is high performance for analytical queries.
8. A data warehouse is a step ahead of
a database. It includes a database in its structure.
Subscribe to:
Posts (Atom)